HTML解析之Beautiful Soup
Beautiful Soup是一个用于从 HTML 和 文件中提取数据的 Python 库Beautiful Soup是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。Beautiful Soup 提供些简单的函数用来处理导航、搜索、修改分析树等功能。Beautiful Soup 模块中的查找提取功能非常强大,而且非常便捷,它通常可以节省程序员大量的工作时间。Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为UTF-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
1、Beautiful Soup 的安装
Beautiful Soup 3 己经停止开发,目前推荐使用的是 Beautiful Soup 4,不过它已经被移植到 bs4 当中了,所以在导入时需要 from bs4 然后再导入Beautiful Soup。安装 Beautiful Soup 有以下三种方式:
方式一:如果您使用的是最新版本的 Debian 或 Ubuntu Linux,则可以使用系统软件包管理器安装 Beautiful Soup 安装命令为: apt-get install python-bs4。
方式二:Beautiful Soup 4 是通过 PyPi 发布的,在 Windows 系统下可以通过 easy_install 或 pip 来安装它。包名是beautifulsoup4,它可以兼容 Python2 和 Python3。安装命令为:easy_install beautifulsoup4 或者是 pip install beautifulsoup4。
在使用 Beautiful Soup 4 之前需要先通过命令pip install bs4 进行 bs4 库的安装。
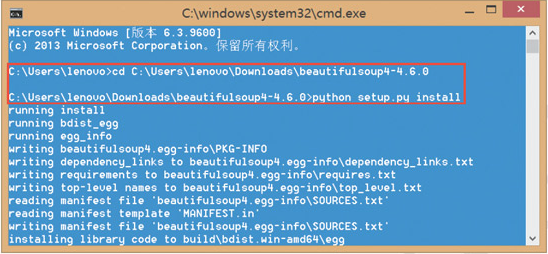
方式三:如果当前的 Beautiful Soup 不是您想要的版本,可以通过下载源码的方式进行安装,源码的下载地址为 “https://www.crummy.com/software/BeautifulSoup/bs4/download/”,然后在控制台中打开源码的指定路径,输入命令“python setup.py install” 即可,如下图所示:
Beautiful Soup 支持 Python 标准库中包含的 HTML 解析器,但它也支持许多第三方 Python 解析器其中包含 lxml 解析器。根据不同的操作系统,您可以使用以下命令之一安装lxml:
本文未完全显示,开通会员查看全文......